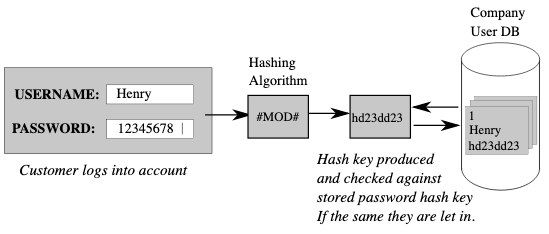
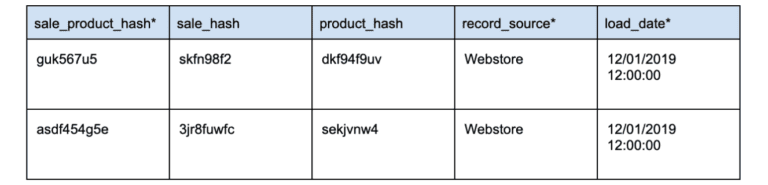
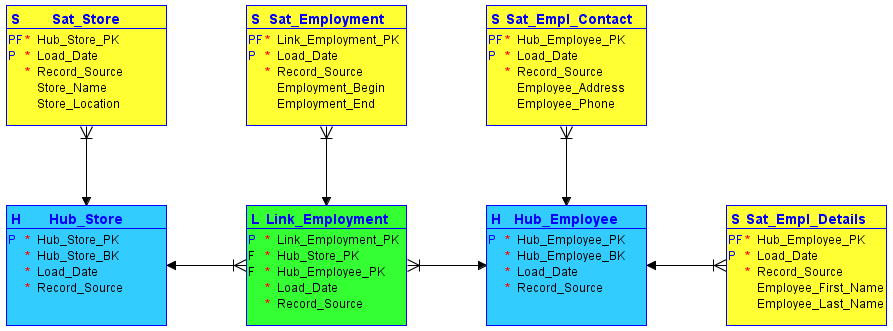
What is Variant data type?
A variant data type is a data type that can store a range of different data types, including numerical, string, and Boolean values. This allows for greater flexibility in storing data, as the same field can be used to store a variety of different types of data.
In some programming languages, the variant data type is called “dynamic” or “any” data type. It is often used in situations where the type of data being stored is not known in advance, or where the data may change over time.
For example, in a Data Vault modelling scenario, a variant data type could be used to store data from a variety of sources, including databases, flat files, and APIs. This allows the Data Vault to accommodate a wide range of data types and formats, without requiring any transformation or cleansing of the data.
Variant data types on Data Vault 2.0
Using variant data types in Data Vault modelling can provide a number of advantages. Some of these advantages include:
- Improved data integrity: By using Variant data types, you can ensure that the data stored in your Data Vault is accurate and consistent, even when the data sources may be inconsistent or incomplete. This helps to ensure the quality and reliability of your data.
- Enhanced flexibility: Variant data types allow you to store data flexibly, which can be helpful when dealing with data that may change over time or may be incomplete. This can help to reduce the need for data cleansing or transformation, as the Data Vault can accommodate a wide range of data types and formats.
- Improved performance: Using variant data types can help improve your Data Vault’s performance, as the system can more efficiently store and retrieve data. This can be particularly important when working with large volumes of data.
- Improved scalability: By using Variant data types, you can more easily scale your Data Vault to accommodate growing volumes of data. This can help to ensure that your Data Vault remains functional and efficient as your data needs change over time.
Overall, using Variant data types in Data Vault modelling can help to improve the accuracy, flexibility, performance, and scalability of your data management system.
Where can I find Variant data types?
Variant data types are supported by a wide range of systems and programming languages. Some examples include:
Databases
- Microsoft SQL Server: In SQL Server, the “sql_variant” data type is used to store values of different data types. This data type can store values of any data type, except for “text,” “ntext,” and “image” data types.
- MySQL: In MySQL, the “JSON” data type is used to store values in a variant data format. The JSON data type can store values of any data type, including arrays and objects.
- PostgreSQL: In PostgreSQL, the “anyarray” data type is used to store arrays of values of any data type. The “anyelement” data type can be used to store values of any data type, including arrays and objects.
- Oracle Database: In Oracle Database, the “ANYDATA” data type is used to store values of any data type. This data type can be used to store values of any type, including integers, strings, and objects.
Cloud database providers
- Amazon Web Services (AWS): AWS offers a number of cloud databases that support variant data types, including Amazon Aurora, Amazon DynamoDB, and Amazon Redshift.
- Microsoft Azure: Microsoft Azure offers a number of cloud databases that support variant data types, including Azure SQL Database, Azure Cosmos DB, and Azure Synapse Analytics (formerly SQL Data Warehouse).
- Google Cloud Platform (GCP): GCP offers a number of cloud databases that support variant data types, including Cloud Bigtable, Cloud Datastore, and Cloud SQL.
- Snowflake: In Snowflake, the “VARIANT” data type is used to store values of different data types in a single field. The VARIANT data type can store values of any data type, including integers, strings, and objects.
In addition to the VARIANT data type, Snowflake also supports a number of other data types, including numeric, string, Boolean, and date/time data types. These data types can be used to store specific types of data in a more efficient manner, depending on the needs of the application or query.
Programming languages
- Python: In Python, the “Any” data type is used to store values of any data type. This data type is part of the “typing” module and can be used to store values of any type, including integers, strings, and objects.
- Java: In Java, the “Object” data type is used to store values of any data type. This data type is part of the Java language and can be used to store values of any type, including integers, strings, and objects.
Variant will help you to develop in a more agile way
Using variant data types can help to create a more agile data warehouse development process by providing greater flexibility in storing and managing data. Some specific ways in which variant data types can improve the agility of data warehouse development include:
- Accommodating changing data sources: By using Variant data types, you can more easily accommodate changes to the data sources that feed your data warehouse. For example, if a new data source becomes available or an existing data source changes its schema, you can use variant data types to more easily incorporate the new data into your data warehouse.
- Simplifying data cleansing and transformation: By using Variant data types, you can often reduce the need for data cleansing and transformation, as the data warehouse can more easily accommodate a wide range of data types and formats. This can help to streamline the data load process and reduce the time and effort required to get new data into the data warehouse.
- Improving query performance: By using Variant data types, you can often improve the performance of queries against your data warehouse, as the system can more efficiently store and retrieve data. This can be particularly important when working with large volumes of data.