Hashing is a technique used to transform a piece of data, such as an identifier, into a fixed-size string of characters, known as a hash. The resulting hash is unique to the input data and has a fixed length, making it useful for various purposes, including data storage and retrieval.
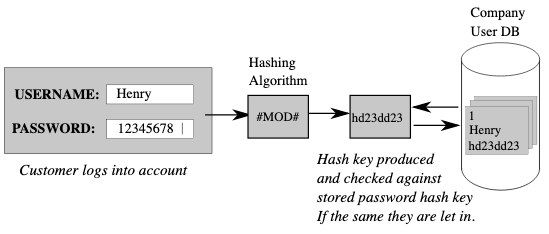
In the context of data vault 2.0, hashing is used to obscure the original values of identifiers in order to protect the privacy of individuals or organizations. By replacing sensitive identifiers with hashed values, it becomes more difficult for unauthorized parties to access or use the original data. This can be especially important when dealing with sensitive or personal information, such as social security numbers or financial data.
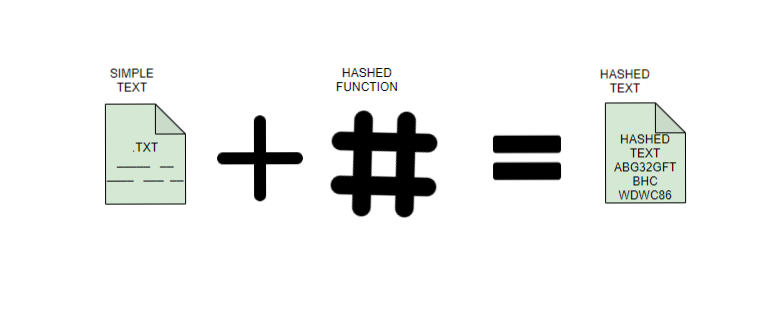
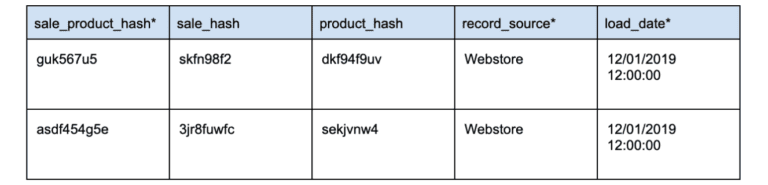
Hashing can also be useful for improving the performance of data management systems by allowing for faster searches and comparisons. When data is stored in a hashed format, it can be more efficiently indexed and retrieved, which can help to reduce the time and resources required to access and process the data.
Overall, hashing is an important technique in data management and can be used to protect the privacy and security of data, as well as improve the performance of data management systems.

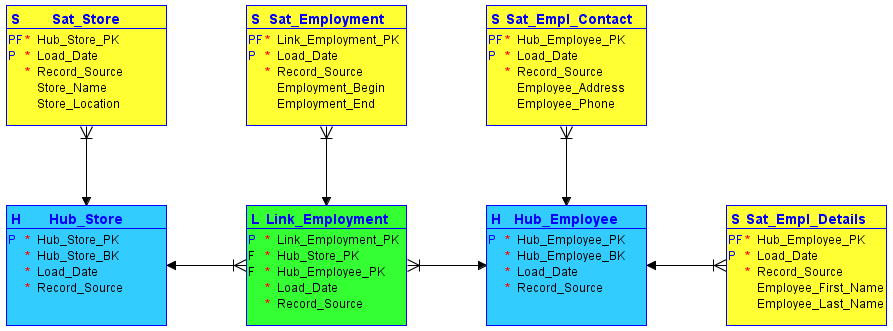
Advantages of Hashing IDs in DV2.0
There are several advantages to hashing identifiers in data vault 2.0:
- Protects privacy: Hashing can help to protect the privacy of individuals or organisations by obscuring sensitive identifiers such as social security numbers or financial data. This can be especially important when dealing with sensitive or personal information.
- Improves security: By replacing sensitive identifiers with hashed values, it becomes more difficult for unauthorized parties to access or use the original data. This can help to improve the overall security of the data vault.
- Improves performance: Hashing can help to improve the performance of data management systems by allowing for faster searches and comparisons. When data is stored in a hashed format, it can be more efficiently indexed and retrieved, which can help to reduce the time and resources required to access and process the data.
- Reduces storage requirements: Hashing can help to reduce the amount of storage space required to store data, as the resulting hash is typically smaller than the original identifier. This can be especially useful when dealing with large datasets.
Overall, hashing is a useful technique in data management and can provide a number of benefits in the context of data vault 2.0.